
有监督学习算法
有监督学习算法主要有决策树、支持向量机(SVM)、朴素贝叶斯、K近邻、随机森林、逻辑回归。
K近邻算法
K近邻算法(k-nearest neighbors,KNN)是一种机器学习方法,根据你距离最近的k 个邻居来判断出你的分类。也就是说,如果离你最近的K个邻居中有5个a分类,2个b分类,那你就属于a分类。可以看出,KNN做分类预测时,一般是选择多数表决法。
KNN不只能做分类,而且可以做回归。我们知道回归一般对连续值进行预测,KNN算法就是用K个邻居的平均值作为预测值。
KNN常用的算法为:
- Brute Force;
- K-D Tree
- Ball Tree。
简单记忆:对于小型数据集,使用Brute Force,对于低维数据,选择K-D Tree,对于高维数据,选择Ball Tree。
代码示例
使用sklearn.neighbors库做演示,详细用法
1 | from sklearn.neighbors import NearestNeighbors |
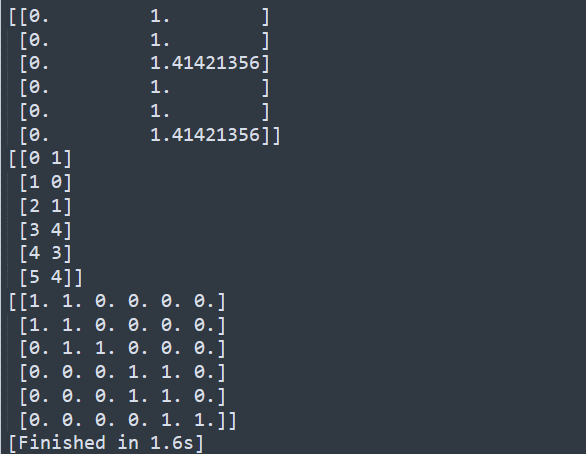
结果预测
1 | from sklearn.neighbors import NearestNeighbors |
异常操作检测
数据集
数据集中包含50个User各15000条命令,对命令进行100一组的分块,前50组命令没有恶意操作,后100组命令随机包含恶意操作,恶意操作标记为1,非恶意则为0,标记文本在此下载,另外,标记文本只包含后100组的结果,训练过程中前50组的0需要自己补齐。
使用前100组作为训练集,后50组作为测试集。
在标记文本中包含50列,100行,第i列代表Useri,第i行代表对应User的第i个命令块的标记结果

SEA伪装者检测1
思路:以命令块为单位即100个命令一组进行K近邻算法训练,每个命令块以出现命令的个数、出现命令与使用频率最高的50个命令的重复数,出现命令与使用频率最低的50个命令的重复数作为每个命令块的特征输入进行训练。
代码存放在此:https://github.com/HacKerQWQ/CyberSecurity_MachineLearning/blob/master/KNN/intrusion_detection_1.py
频率需要使用到nltk的probability库中的FreqDist方法
1 | from nltk.probability import FreqDist |
获取频率最高的50个和最低的50个命令
1 | # dist包含该用户所有命令键值对,命令:出现个数的形式 |
生成特征
1 | f1=len(set(cmd_block)) |
x的格式如下
[29, 10, 0]
[29, 10, 0]
[23, 6, 1]
[6, 6, 0]
[15, 9, 1]
[16, 10, 0]
最后对数据进行训练
1 | # 训练集取前100组 |
结果如下:
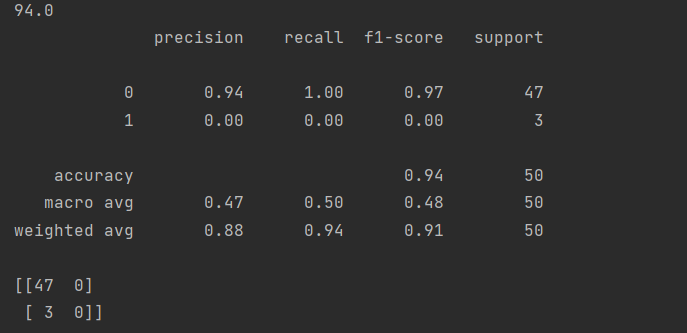
最终结果表现为94%的准确率
SEA伪装者检测2
思路:跟上一步的区别在于这次训练的使用的特征由操作命令向量组成,进行全量比较。
代码:https://github.com/HacKerQWQ/CyberSecurity_MachineLearning/blob/master/KNN/intrusion_detection_2.py
操作命令向量生成:
1 | user_cmd_feature=[] |
v如下

最后使用交叉验证,10次随机取样和验证
1 | print(cross_val_score(neigh,user_cmd_feature,y,n_jobs=-1,cv=10)) |
结果为

Rootkit检测
数据集
选用KDD99数据集:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
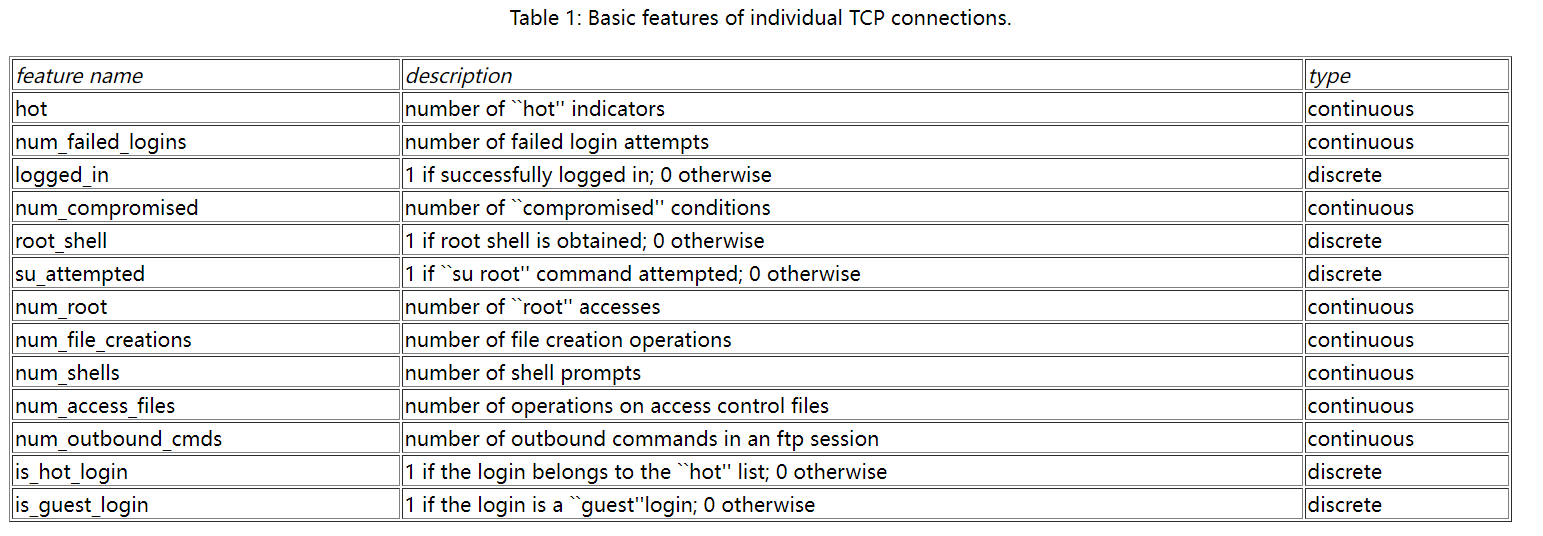
数据格式如图

Rootkit检测过程
总共41个特征,根据官网给出的特征表,选用中间10-22个特征。
思路:选用基于telnet协议的流量进行研究,将normal标记为0,rootkit标记为1,10-22共13个特征作为输入,使用KNN作为算法进行模型训练和预测。
以下是提取telnet协议的流量,并且生成y数据集。
1 | def get_rootkit2andNormal(x): |
KNN训练并且使用K折验证效果
1 | clf = KNeighborsClassifier(n_neighbors=3) |

Webshell检测
数据集
数据集使用ADFA-LD,文件夹中包括训练集、攻击数据集,包含Linux和Windows的系统调用对应的数字代码。

Webshell检测过程
这里使用Attack_Data_Master文件夹下的Web_Shell系列文件夹下的文本文件以及Training_Data_Master下的文本文件作为训练集。
采用词袋模型处理训练集形成向量
1 | vectorizer = CountVectorizer(min_df=1) |
将training文件夹下的文件输入的数据标记为0,attack文件夹下的则标记为1.
使用KNN训练
1 | clf = KNeighborsClassifier(n_neighbors=3) |
效果验证
1 | scores=cross_val_score(clf, x, y, n_jobs=-1, cv=10) |

平均有96%的准确率。