
神经网络&机器学习
神经网络和机器学习基础入门:https://blog.csdn.net/qq_22521211/article/details/81011099
词汇解释
- 人工神经网络(artificial neural network,缩写ANN)
- 神经元(neuron)
- 深度学习(Deep Learning)
- 机器学习(Machine Learning)
- 神经语言程序学(Neuro-Linguistic Programming,NLP)
- 分类(Classification):输入的训练数据有特征(feature),有标签(label)。
- 聚类(Clustering): 输入的训练数据没有标签,跟分类相对
机器学习介绍
- 学习的本质就是找到特征和标签间的关系(mapping)
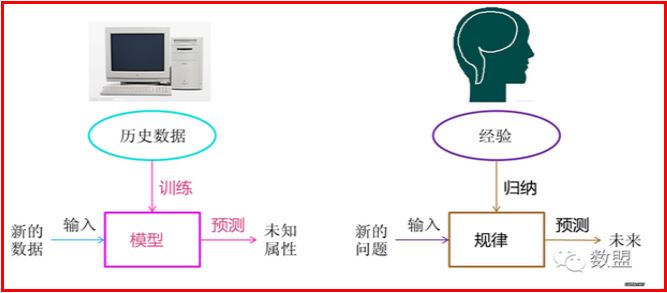
机器学习方法是计算机利用已有的数据(经验),得出了某种模型(迟到的规律),并利用此模型预测未来(是否迟到)的一种方法。
- 机器学习简单来说就是让机器模拟人的思考过程,从而具备“学习”的能力
下图很好的概括了这一过程
机器学习主要的方向有

- 模式识别=机器学习
- 数据挖掘=机器学习+数据库
- 计算机视觉=图像处理+机器学习(图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。例如百度识图、手写字符识别、车牌识别等等应用。)
- 统计学习≈机器学习(机器学习中的大多数方法来自统计学,甚至可认为统计学的发展促进机器学习的繁荣昌盛。统计学偏数学,机器学习偏实践)
- 语音识别=语音处理+机器学习(音频处理技术和机器学习的结合,产物如小爱同学、siri)
- 自然语言处理=文本处理+机器学习(让机器理解人类的语言,词法分析、语法分析、语义理解等)
最简单机器学习算法
学习的本质就是找到特征和标签间的关系(mapping)。这样当有特征而无标签的未知数据输入时,我们可以通过已有的关系得到未知数据的标签。
机器学习分类
机器学习分为监督学习、无监督学习、半监督学习、深度学习、强化学习、迁移学习。
监督学习(Supervised learning,SL),训练集中的样本都有标签,训练中能够通过这些标签对样本进行划分,可以将监督学习分为分类和回归两种问题,分类问题预测的是样本类别(离散的),回归问题预测的是样本对应的实数输出(连续的)。
常见算法有决策树、支持向量机(SVM)、朴素贝叶斯、K近邻、随机森林、逻辑回归
无监督学习(Unsupervised learning,UL),与监督学习相对,样本无标签,训练出的模型精度会降低,UL相较SL有难度。主要用于聚类、降维问题
常见算法有聚类算法(K均值、AP聚类和层次聚类)和降维算法(主成分分析)
半监督学习(Semi-Supervised Learning,SSL),介于SL和UL之间,样本由少量标记和大量未标记组成
深度学习(Deep learning,DL),深度学习的训练样本是多标签的,试图使用复杂结构或多重非线性变换构成的多个处理层对数据进行高层抽象。深度学习在入侵检测、图像识别、语言处理和识别等方面作用不菲,也是人工智能技术的重要组成部分。
强化学习(Renforcemet learning,RL),样本使用未标记的训练集,其核心是描述并解决智能体在与环境交互的过程中学习策略以最大化回 报或实现特定目标的问题。RL背后的数学原理与 SL 或 UL略有差异,SL或 UL主要应用的是统计学,RL则 更多地使用了随机过程、离散数学等方法。
常见算法有Q-学习算法、瞬时差分法、自适应启发评价算法等
迁移学习(Transfer Learning,TL),指的是根据任 间的相似性,将在辅助领域之前所学的知识用于相似却不相同的目标领域中来进行学习,有效地提高新任 务的学习效率。迁移学习可分为基于样本、基于参数、 基于特征表示和基于关系知识的四类迁移方式。
SL、SSL和 UL是传统 ML 方法;DL提供了一个更 强大的预测模型,可产生良好的预测结果;RL提供了 更快的学习机制,且更适应环境的变化;TL突破了任 务的限制,将 TL应用于 RL中,能帮助 RL更好地落实 到实际问题。各个分类的关系如下:
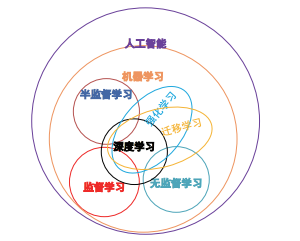
机器学习过程
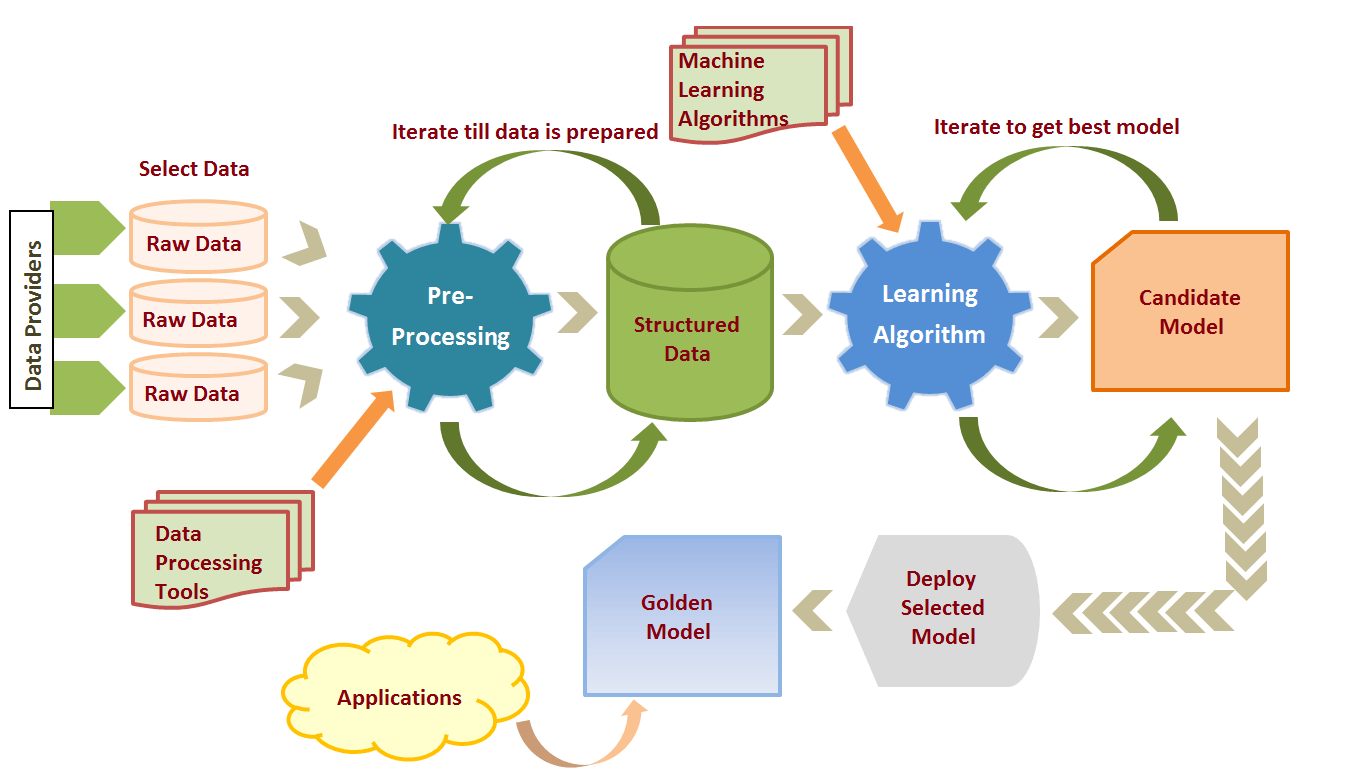
- 收集数据
- 准备该数据
- 选择模型
- 训练
- 评估
- 超参数调整
- 预测
经典数据集
KDD 99
网址:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
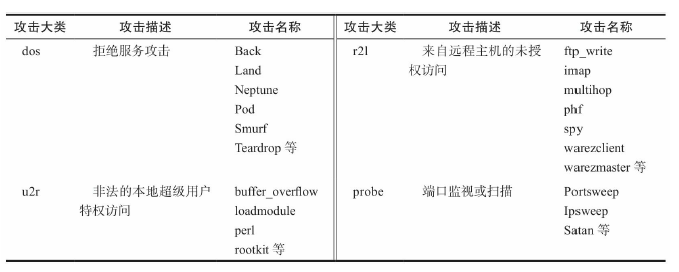
介绍:KDD(Knowledge Discovery and Data Mining)收集了9周的网络连接和系统审计数据,方针各种用户类型、各种不同的网络流量网络流量和攻击手段。每个网络连接被标记为正常(normal)**或异常(attack)**,异常被分为4大类共39中攻击类型。其中22中出现在训练集中,另外17种出现在测试集。
详细看:http://kdd.ics.uci.edu/databases/kddcup99/task.html
用途:用于检测网络入侵的研究
HTTP DATASET CSIC 2010
网址:https://www.isi.csic.es/dataset/
介绍:该数据集包括数以千计的自动生成的web请求。
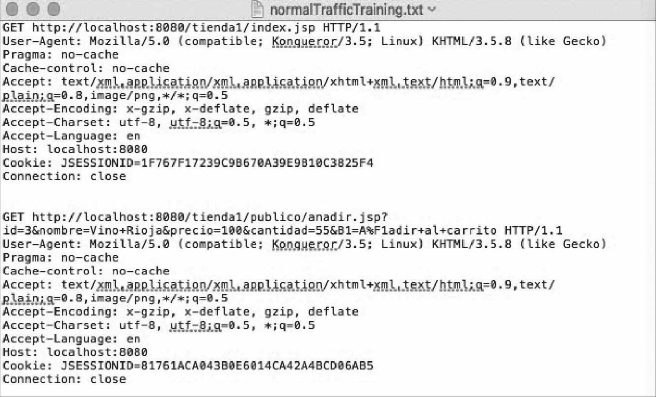
正常请求
异常请求
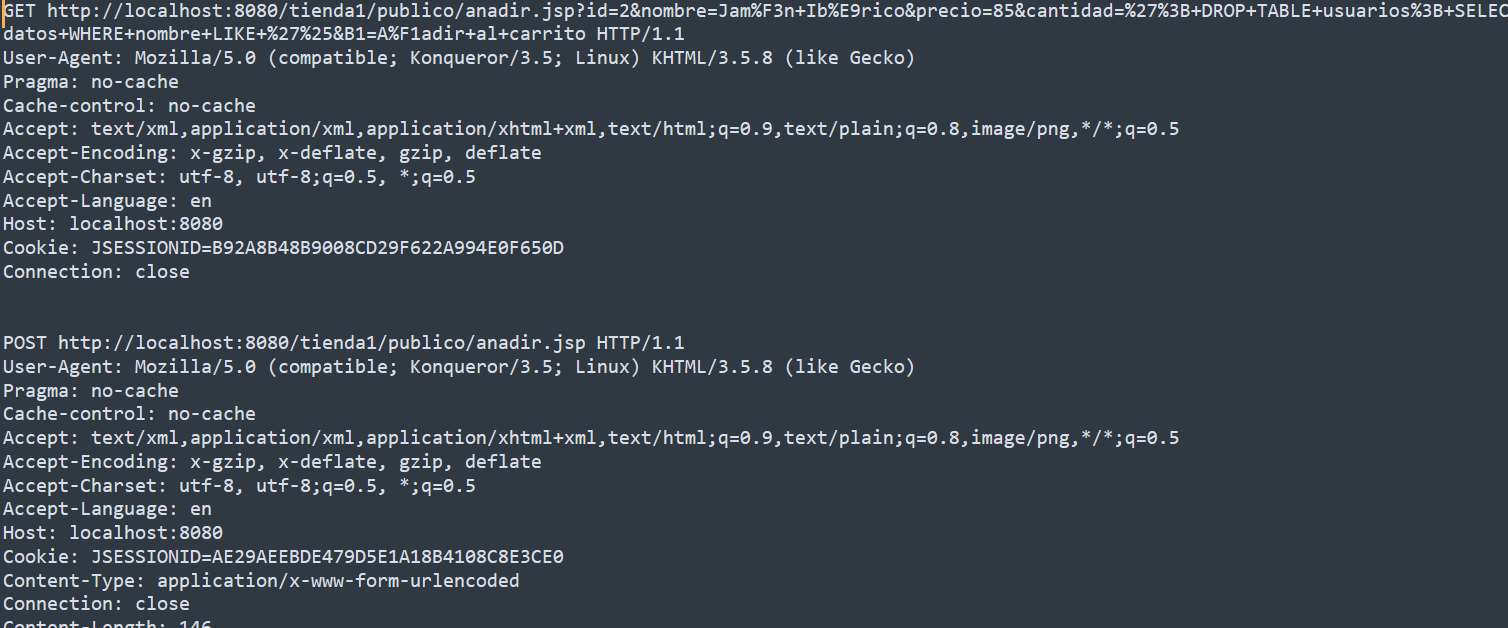
用途:测试web攻击防护系统
SEA数据集
介绍:2001年Schonlau等人第一次将内部攻击者分类为“叛徒”(Traitor)与“伪装者”(Masquerader),其中“叛徒”指攻击者来源于组织内部,本身是内部合法用户;而“伪装者”指外部攻击者窃取了内部合法用户的身份凭证,从而利用内部用户身份实施内部攻击。
用途:用于内部伪装者威胁检测研究

ADFA-LD数据集
网址:https://research.unsw.edu.au/projects/adfa-ids-datasets
介绍:ADFA-LD数据集是澳大利亚国防学院对外发布的一套主机级入侵检测系统的数据集合,被广泛应用于入侵检测类产品的测试。该数据集包括Linux和Windows,记录了系统调用数据
用途:用于入侵检测类产品的测试
Alexa域名数据
网址:http://s3.amazonaws.com/alexa-static/top-1m.csv.zip
介绍:该数据集由前 100 万个网站的 URL 组成。这些域使用 Alexa 流量排名进行排名,该排名是根据用户在网站上的浏览行为、唯一访问者的数量和网页浏览量的组合确定的。更详细地说,唯一访问者是在给定日期访问网站的唯一用户的数量,而综合浏览量是对网站的用户 URL 请求的总数。但是,同一天对同一网站的多次请求被计为一次综合浏览量。独立访问者和综合浏览量组合最高的网站排名最高。
Scikit-Learn数据集
介绍:该数据集由 3 种不同类型的鸢尾花(Setosa、Versicolour 和 Virginica)花瓣和萼片长度组成,存储在 150x4 numpy.ndarray 中行是样本,列是:萼片长度、萼片宽度、花瓣长度和花瓣宽度。
MNIST数据集
网址:http://yann.lecun.com/exdb/mnist/
介绍:MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片。每一个MNIST数据单元由两部分组成:一张包含手写数字的图片和一个对应的标签。每一张图片包含28×28个像素点,可以把这个数组展开成一个向量,长度是28×28=784。
导入代码:
1 | # 使用keras框架导入 |
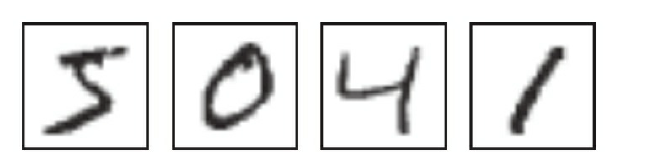
Movie Review Data
网址:https://www.cs.cornell.edu/people/pabo/movie-review-data/
介绍:Movie Review Data数据集包含1000条正面的评论和1000条负面评
论,被广泛应用于文本分类,尤其是恶意评论识别方面。本书使用其最
新的版本,polarity dataset v2.0。
SpamBase数据集
网址:http://archive.ics.uci.edu/ml/datasets/Spambase
介绍:SpamBase是入门级的垃圾邮件分类训练集,SpamBase的数据不是原始的邮件内容而是已经特征化的数据,对应的特征是统计的关键字以及特殊符号的词频,一共58个属性,其中最后一个是垃圾邮件的标记位。
Enron数据集
网址:https://www2.aueb.gr/users/ion/data/enron-spam/
介绍:Enron公司的归档邮件来研究文档分类、词性标注、垃圾邮件识别等,由于Enron的邮件都是真实环境下的真实邮件,非常具有实际意义。Enron数据集是经过人工标注过的正常邮件和垃圾邮件,属于狭义的Enron数据集合,广义的Enron数据集指全量真实且未被标记的Enron公司归档邮件。
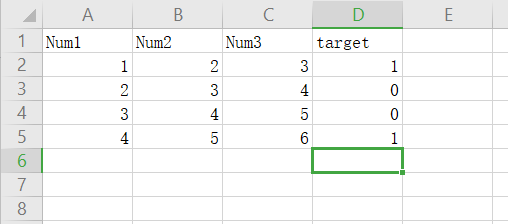
数据提取
csv读取
用tensorflow进行数据读取
csv数据
1 | import tensorflow as tf |

更多参数:https://www.tensorflow.org/api_docs/python/tf/data/experimental/make_csv_dataset
特征工程
在训练过程中常见的特征有数字型特征和文本型特征。
数字型特征提取
数字型特征可以直接作为特征输入,但是对于多维的特征,为了防止某一维的范围过大,需要对数字型特征进行预处理。
标准化(Standardization)
将数据集中某一列数值特征的值缩放成平均值为0,标准差为1的状态
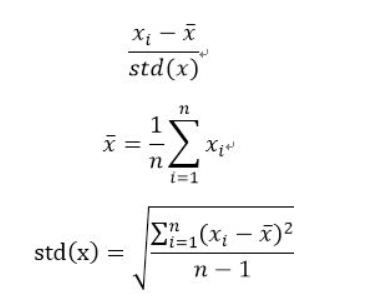
1
2
3
4
5
6
7
8
9
10from sklearn import preprocessing
import numpy as np
X = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
X_scaled = preprocessing.scale(X)
X_scaled
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])标准化更符合统计学假设。对于一个数值特征来说,很大可能它是服从正太分布的,而标准化是基于这个假设,将正态分布调整为标准正态分布;
归一化(Normalization)
将数据集中某一列数值特征缩放到0-1区间内
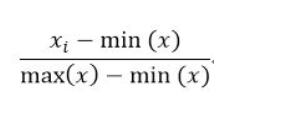
x是指一列的值,x_i是列中的每一个,min(x)是这一列的最小值,max(x)是这一列的最大值。
当要求特征必须是在0-1之间的,此时必须要使用归一化。1
2
3
4
5
6
7
8
9
10
11from sklearn import preprocessing
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
...
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])正则化(Regularization)
将数据集中某一个样本缩放成单位标准
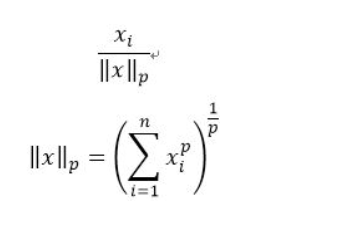
1
2
3
4
5
6
7
8
9from sklearn import preprocessing
X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
X_normalized = preprocessing.normalize(X, norm='l2')
X_normalized
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])正则化(normalization)与归一化和标准化不同,归一化和标准化是对数据集中的列进行的操作,而正则化是对数据集中的行进行的操作。
常见的正则化是L2正则化,即使用L2范数,这也就是将向量单位化的过程。
文本类型特征提取
文本类型的数据无法直接作为输入进行训练,因此需要对文本类型进行转换后进行输入。
One-Hot编码
One-Hot表示是把语料库中的所有文本进行分词,把所有单词(词汇)收集起来,并对单词进行编号,构建一个词汇表(vocabulary),词汇表是一个字典结构,key是单词,value是单词的索引
1 | vocabulary = { 'one':0,'hot':1, ...'term':n-1} |
如果词汇表有n个单词构成,那么单词的索引从0开始,到n-1结束。
有了词汇表之后,就可以使用向量来表示单个词汇。每一个词汇都表示为一个由n列构成的向量,称作词向量,词向量的第0列对应词汇表(vocabulary)中的第0号索引,词向量的第1列对应词汇表(vocabulary)中的第1号索引,依次类推。
词汇向量有n列,但是只有一列的值为1,把值为1的列的索引带入到词汇表(vocabulary)中,就可以查找到该词向量表示的词汇,也就是说,对于某个单词 term,如果它出现在词汇序列中的位置为 k,那么它的向量表示就是“第 k 位为1,其他位置都为0 ”,这就是One-Hot(独热)名称的由来。
例如,有语料库(corpus)如下:
John likes to watch movies. Mary likes movies too.
John also likes to watch football games.
把上述语料中的词汇整理出来并进行排序(具体的排序原则可以有很多,例如可以根据字母表顺序,也可以根据出现在语料库中的先后顺序),假设我们的词汇表排序结果如下:
1 | {"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also":6, "football": 7, "games": 8, "Mary": 9, "too": 10} |
那么,得出如下词向量表示:
1 | John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
One-Hot方法很简单,但是它的问题也很明显:
- 没有考虑单词之间的相对位置,任意两个词之间都是孤立的;
- 如果文档中有很多词,词向量会有很多列,但是只有一个列的值是1;
sklearn实现one hot encode
1 | from sklearn import preprocessing |
词袋模型(Bag of Words)
BoW把文本转换为文档中单词出现次数的矩阵,该模型只关注文档中是否出现给定的单词和单词出现频率,而舍弃文本的结构、单词出现的顺序和位置。
例子:
1 | "John likes to watch movies, Mary likes movies too" |
对于这两个句子,我们要用词袋模型把它转化为向量表示,这两个句子形成的词表(不去停用词)为:
1 | [‘also’, ‘football’, ‘games’, ‘john’, ‘likes’, ‘mary’, ‘movies’, ‘to’, ‘too’, ‘watch’] |
因此,它们的向量表示为:
代码示例
- 经典创建Bow模型
1 | # 引入CountVectorizer |

复用已有词汇表
1
2vocabulary=vectorizer.vocabulary_
new_vectorizer = CountVectorizer(min_df=1, vocabulary=vocabulary)
参数解释:
1 | CountVectorizer(input=’content’, encoding=’utf-8’, decode_error=’strict’, strip_accents=None, |
- input:默认值是content,表示输入的是顺序的字符文本
- decode_error:默认为strict,遇到不能解码的字符将报UnicodeDecodeError错误,设为ignore将会忽略解码错误
- lowercase:默认值是True,在分词(Tokenize)之前把文本中的所有字符转换为小写。
- preprocessor:预处理器,在分词之前对文本进行预处理,默认值是None
- tokenizer:分词器,把文本字符串拆分成各个单词(token),默认值是None
- analyzer:用于预处理和分词,可设置为string类型,如’word’, ‘char’, ‘char_wb’,默认值是word
- stop_words:停用词表,如果值是english,使用内置的英语停用词列表;如果是一个列表,那么使用该列表作为停用词,设为None且max_df∈[0.7, 1.0)将自动根据当前的语料库建立停用词表
- ngram_range:tuple(min_n,max_n),表示ngram模型的范围
- max_df:可以设置为范围在[0.0 1.0]的浮点数,也可以设置为没有范围限制的整数,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的词汇表时,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效
- min_df:类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词
- max_features:对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集
- vocabulary:默认为None,自动从输入文档中构建关键词集,也可以是一个字典或可迭代对象。
- binary:默认为False,一个关键词在一篇文档中可能出现n次;如果binary=True,非零的n将全部置为1,这对需要布尔值输入的离散概率模型的有用的
- dtype :用于设置fit_transform() 或 transform()函数返回的矩阵元素的数据类型
模型的属性和方法:
- vocabulary_:词汇表,字典类型
- get_feature_names_out():所有文本的词汇,列表型
- stop_words_:停用词列表
模型的主要方法:
- fit(raw_document):拟合模型,对文本分词,并构建词汇表等
- transform(raw_documents):把文档转换为文档-词矩阵
- fit_transform(raw_documents):拟合文档,并返回该文档的文档-词矩阵
TF-IDF
IF-IDF是信息检索(IR)中最常用的一种文本表示法。算法的思想也很简单,就是统计每个词出现的词频(TF),然后再为其附上一个权值参数(IDF)。举个例子:
假设要统计一篇文档中的前10个关键词.首先想到的是统计一下文档中每个词出现的频率(TF),词频越高,这个词就越重要。但是统计完你可能会发现你得到的关键词基本都是“的”、“是”、“为”这样没有实际意义的词(停用词),这个问题怎么解决呢?你可能会想到为每个词都加一个权重,像这种”停用词“就加一个很小的权重(甚至是置为0),这个权重就是IDF。下面再来看看公式:
IF应该很容易理解就是计算词频,IDF衡量词的常见程度。为了计算IDF我们需要事先准备一个语料库用来模拟语言的使用环境,如果一个词越是常见,那么式子中分母就越大,逆文档频率就越小越接近于0。这里的分母+1是为了避免分母为0的情况出现。TF-IDF的计算公式如下: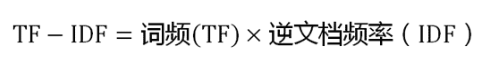
根据公式很容易看出,TF-IDF的值与该词在文章中出现的频率成正比,与该词在整个语料库中出现的频率成反比,因此可以很好的实现提取文章中关键词的目的。
优缺点分析
优点:简单快速,结果比较符合实际
缺点:单纯考虑词频,忽略了词与词的位置信息以及词与词之间的相互关系。
sklearn实现tfidf
1 | from sklearn.feature_extraction.text import CountVectorizer |
效果验证
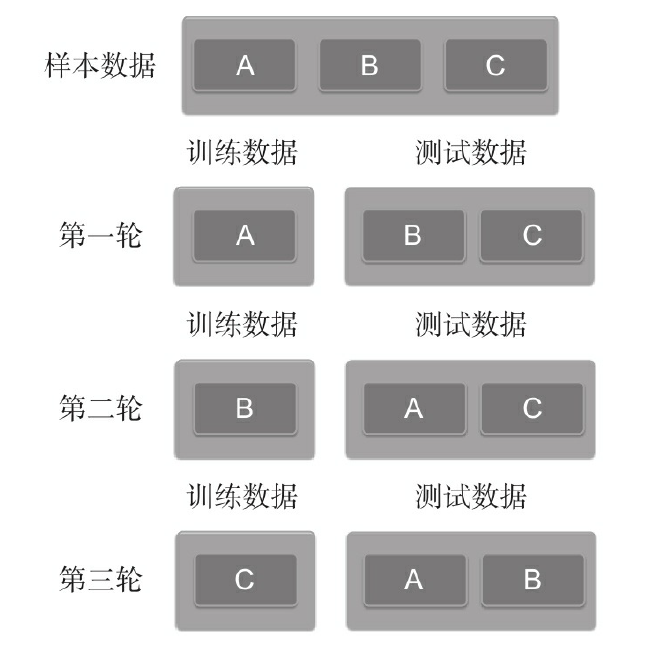
常用的效果验证方法是交叉验证。
所谓K折交叉验证,就是初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其他结合方式,最终得到一个单一估测。
1 | from sklearn.model_selection import cross_val_score |
神经网络介绍
神经网络是深度学习最强大的算法之一
神经网络还得从神经元开始说起
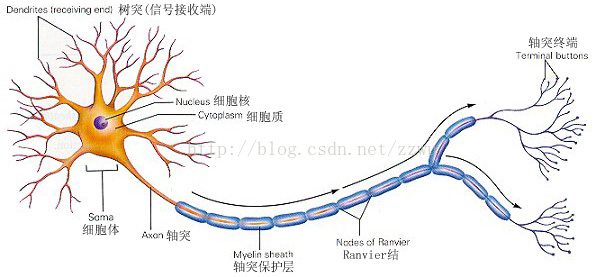
高中生物就学过神经元,树突(dendrite)用于接收其他神经元从轴突传输过来的递质,然后在轴突(Terminal buttons)上通过电信号进行传递,最后在轴突上通过递质传递到下一个神经元的树突(或胞体式突触、轴突)上,是化学信号-电信号-化学信号的传递
神经细胞通过轴突将信号传递给其他的神经细胞,通过树突向各个方向接受信号
上一个神经元的轴突和本神经元的树突形成的结构叫突触
神经网络还有一个重要的机制:当从树突上接收到的信号达到某个阈值时,神经元会进入兴奋(file)状态,产生电信号传递到其他神经元,否则就不会产生电信号,为抑制状态
- 这个机制对应到计算机上就是,兴奋状态表示1,抑制状态表示0
人工神经网络的特点
大脑的特点如下:
- 能实现无监督的学习
大脑能够自己进行学习,而不需要导师的监督教导。如果一个神经细胞在一段时间内受到高频率的刺激,则它和输入信号的神经细胞之间的连接强度就会按某种过程改变,使得该神经细胞下一次受到激励时更容易兴奋。 - 对损伤有冗余性(tolerance)
大脑即使有很大一部分受到了损伤, 它仍然能够执行复杂的工作。 - 处理信息的效率极高
神经细胞之间电-化学信号的传递,与一台数字计算机中CPU的数据传输相比,速度是非常慢的,但因神经细胞采用了并行的工作方式,使得大脑能够同时处理大量的数据。例如,大脑视觉皮层在处理通过我们的视网膜输入的一幅图象信号时,大约只要100ms的时间就能完成,眼睛并发执行。 - 善于归纳推广
大脑和数字计算机不同,它极擅长的事情之一就是模式识别,并能根据已熟悉信息进行**归纳推广(generlize)**。例如,我们能够阅读他人所写的手稿上的文字,即使我们以前从来没见过他所写的东西。 - 它是有意识的
同样的,要实现神经网络的学习功能,就是要实现上面的人脑特点
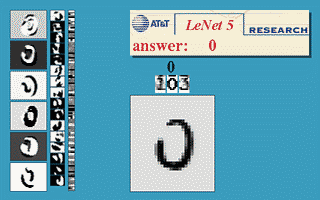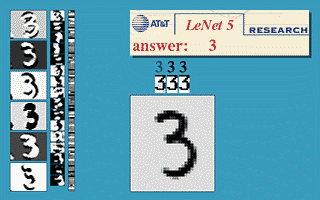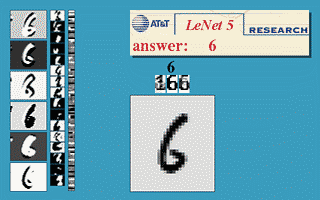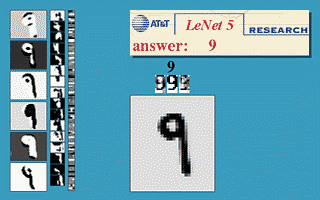
机器学习的几个问题
无监督学习和有监督学习
所有训练数据都有标签则为有监督学习(Supervised Learning),如果数据没有标签则是无监督学习(Unsupervised Learning),也即聚类(Clustering)。但有监督学习并非全是分类还有回归(Regression)。半监督学习
无监督学习和有监督学习的中间带就是
半监督学习(semi-supervised learning)。对于半监督学习,其训练数据的一部分是有标签的,另一部分没有标签,而没标签数据的数量常常极大于有标签数据数量(这也是符合现实情况的)。
- 简单理解:有监督学习就是做题有答案,无监督学习就是做题没有答案,效果是有监督学习更好,但是耗费人力物力贴标签。